Operating Systems: HW 4
Due Monday November 29, 2010
Answer each of the following questions. Please submit your solution through Spark.
1. (10 points) Describe both internal and external fragmentation. What are techniques that can be used to reduce each of these?
2. (5 points) How do paging systems deal with the fact that memory pages are distributed across the RAM in a non-contiguous way?
3. (5 points) What additional complexity does segmented paging incur? What are its benefits?
4. (20 points) Consider a system with 32Byte pages/frames and a total memory size of 512Bytes. Assume it is a typical 32bit system and thus can access memory with 4 byte (word level) granularity. This means that memory can only be addressed at word level granularity--thus an offset of 0 within a page implies the first word (e.g. bytes 0 to 3) of the page, while an offset of 1 refers to the second word (bytes 4-7).
(a.) What is the total number of addressable words supported by this memory? How many different pages can it support?
(b.) In each virtual address on this system, how many bits are needed for the page number (p) and how many for the offset (d)?
(c.)
Use the above information and the following page table to translate virtual address "31" to a physical address.

To receive any partial credit, show the following: values of p and d, the frame number corresponding to p, the fully translated address.
Hint: to verify your methodology, you can check that virtual address 12 maps to physical address byte 208 (frame 6, offset 4)
5. (10 points) Suppose you want to run a set of applications which in total will require more memory than your system has. What are two memory management techniques that modern operating systems might use to support running all of these applications simultaenously?
6. (20 points) Determine how the FIFO and MIN page replacement schemes would each handle the following page access pattern. Assume that the system has three frames (F1, F2, and F3), and that each frame can hold a single virtual page (A, B, C, D, or E). Fill in how the frames are mapped for the following access stream, and report the number of page hits and page faults for each algorithm.
| FIFO |
A |
B |
C |
D |
E |
A |
B |
E |
D |
B |
B |
A |
| F1 |
|
|
|
|
|
|
|
|
|
|
|
|
| F2 |
|
|
|
|
|
|
|
|
|
|
|
|
| F3 |
|
|
|
|
|
|
|
|
|
|
|
|
| Number of hits: |
|
| MIN |
A |
B |
C |
D |
E |
A |
B |
E |
D |
B |
B |
A |
| F1 |
|
|
|
|
|
|
|
|
|
|
|
|
| F2 |
|
|
|
|
|
|
|
|
|
|
|
|
| F3 |
|
|
|
|
|
|
|
|
|
|
|
|
| Number of hits: |
|
7. (20 points) Consider the file architecture shown in the following figure. For each file there is an Index structure which contains 8 entries: the first 7 are pointers to 1KB data blocks and the last points to a Secondary Index data structure which contains 8 more data pointers.
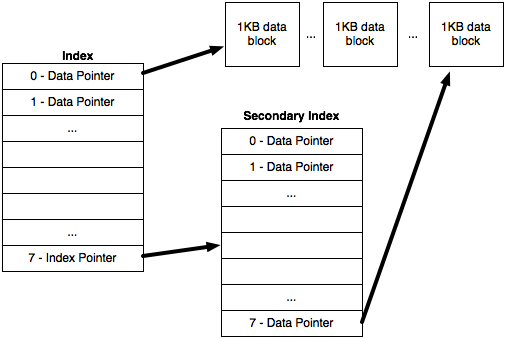
(a.) What is the maximum size of a file using this architecture?
(b.) If you increased the number of entries in both data structures from 8 to 32 (but still kept only one Index Pointer in the Index), how would that impact the size of allowable files? Would it impact the performance of file accesses? How?
(c.) What simple change could you make to this structure to support files of infinite size?
8. (10 points) (a.) What is the order of seeks for the following set of requests when using the SSTF and SCAN disk scheduling algorithms? What is the total distance of seeks in each case?
Disk Request Queue: 44, 57, 78, 65, 46, 90
Assume that the disk has its head at position 45 out of 100 and that it is currently moving towards higher numbers (for SCAN).
(b.) Describe a scenario where the algorithm which performed best in part (a.) will actually perform worse than the other algorithm. (Provide a disk request queue with at least six entries in it and show why the performance is worse)
Prashant Shenoy